A found tapes meta-map
november 08, 2009.
After the das kleine performances I had an interesting discussion with some of the visitors saturday
october 17th at the Leipziger gal.lery,
on the subject of Penelope's
recordings.
To begin, it surprised me to find that they (all students of Leipzig University,
though in very different subjects) did not seem to be bothered too much
by the very considerable material and physical difficulties of Penelope's
odyssey. The task that she performed was titanic, maybe not in
absolute terms, but definitely as far as one single person goes. Not in
absolute terms, as the use of on the average 21 cassette tapes per day will
have been far below the daily tape turnover of a retail shop in whatever
reasonably sized Western city in the heydays of the compact-cassette. A
quick calculation shows that stacking all of the cassettes that went through
Penelope's hands in the twenty years of her recording project would fill
up just a bit over 20 cubic meter of space . ") To give you an idea how much - or how little - that is: all of
them would easily fit into the medium sized truck that you see in the picture,
which has a capacity of about 25 cubic meters. (Mind you though that the
truck in the picture would not be suitable to transport the cassettes.
The block of tapes would weigh about 10 tons, while the truck as pictured
is apt to transport loads up to 7.5 tons only...)
To give you an idea how much - or how little - that is: all of
them would easily fit into the medium sized truck that you see in the picture,
which has a capacity of about 25 cubic meters. (Mind you though that the
truck in the picture would not be suitable to transport the cassettes.
The block of tapes would weigh about 10 tons, while the truck as pictured
is apt to transport loads up to 7.5 tons only...)
I was actually somewhat disappointed when I first realized that for storing
twenty years of audio-recordings on compact cassette one needs but relatively
little space. That was when Penelope showed me the cellar in Meerssen where
she kept them all. I would have estimated one and a half hundred thousand
tapes to take up far more room, but no: all of the sounds of one's life's
best years, written onto 4.75 centimeters of plastic ribbon per second,
together not even completely fill up a medium-sized truck...
[ One of the events related to Penelope's tapes that in the near future I will attempt to realize: display (given a suitable place and the right conditions) her complete archive as a 20 cubic meter solid block of cassettes ... ]
Also Penelope herself originally largely over-estimated the actual volume of tape that was involved. For a while she had been developing the idea to, at the very end of it all, somehow slice all tapes together, and find a way to - physically - take the resulting mega-tape on a world tour and film a documentary of its (un)winding, while making a full circle around the globe. She gave up on that when she found out that in fact the total length of tape that she had used at the end of her twenty years amounted to somewhat less than twelve and a half thousand kilometers. It thus would not even get her one third of the way around.
But we all will agree that for one individual to handle 144.567 cassette tapes of course is gigantic, not even to mention once again the relentless, clock-like 24/7 regularity, that Penelope imposed upon herself for twenty years in one long stretch without breaks: it was a continuous and virtually unending ritual.
The students that I spoke to, though, were not so much interested
in quantities and volumes. They were far more curious to learn about the
social aspects. And especially the girl was eager to find out what sort
of a relationship I had with this Penelope. "Have you known each other
for a long time? How did you meet? Where is she now? And why does she allow you to access and use these personal
recordings?"
 It showed on her face that she tried to imagine how it would feel to - first - record
all of your deeds and doings, and then - second - hand all of it over to some artist type, who would
listen to all of your [[ sleeping, showering, shitting, eating, working,
drinking, shouting, kicking, fucking, bathing, sleeping ]] and divulge it in places much like the one on the cold landing of which we were
standing, smoking and drinking a beer.
It looked as if
the mere thought of it made her shudder, more than did the draught.
It showed on her face that she tried to imagine how it would feel to - first - record
all of your deeds and doings, and then - second - hand all of it over to some artist type, who would
listen to all of your [[ sleeping, showering, shitting, eating, working,
drinking, shouting, kicking, fucking, bathing, sleeping ]] and divulge it in places much like the one on the cold landing of which we were
standing, smoking and drinking a beer.
It looked as if
the mere thought of it made her shudder, more than did the draught.
...
Penelope's recordings and her archive of tapes are among the subjects of a book on the noble art that is foundtaping, which
I currently am in the process
of writing/assembling.
The text concentrates on the tapes that over the years I picked up in the
Netherlands. Its main language will be dutch, but as substantial
parts will be in English (adapted from some of the entries on the subject that
have appeared over the years
in the SoundBlog), it might be of interest also to non-Dutch readers.
The title will be:
"Alle Geluid Van De Wereld" (All sounds in the universe).
The book started out as an introduction and extended offline 'manual' to the
Found Tapes Maps, that I have been working on over the year.
Thanks to a project-grant of
the Netherlands Foundation for Visual Arts, Design and Architecture, I was able
to spend the time necessary not only
to finally bring the
online exhibition up to date with the actual findings, but also to create and maintain a database of all the finds
(at the time of writing that is 664 items), which soon will allow you to visit the found tapes collection
in other than just the current chronological way, for example via
a Googlemaps based interface.
The following Googlemap pictures the area just a little to the north of Paris where four suburbs meet: Pantin, Aubervilliers, Bobigny and La Courneuve.
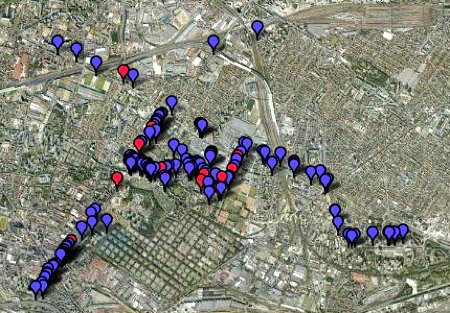
For several years I have been teaching at the IUT Bobigny, part of the Paris XIII University.
I then went to Bobigny
once, sometimes twice a week, during semester periods. I walked up to the campus from one
metro stop or another, did my teaching, and then walked back again. Sometimes I stayed over for lunch.
When
the weather was fine, I went out for a walk.
And when I did, I often came upon some piece or other of cast-away tape.
Where that was,
you see indicated on the map above.
The Bobigny campus is right in its middle.
Isn't it amazing to see how over the years my steps to and from the Bobigny university campus literally became tape-spangled?
It was also over in Bobigny that I picked up what became the very first
item in the Found
Tapes Exhibition, on march 21st, 2002. The about 13 hours long found tapes audio stream
starts with a fragment
from "Okie
from Muskogee", which I found on that Bobigny tape.
I began writing the SoundBlog at about that same time; so these found tapes were among
the first
things that I wrote about, in early september 2002, and some of the blog's
readers helped me to identify these earliest bits of 'found music'. A little later
I thought up my own
web-based ad-hoc method for identifying
fragments of pop music. It was a bit laborious, but worked rather well.
To use it
tracks had to be songs, though, written in a language that I understood.
And the audio fragments had to include part of the lyrics. (I would
search
the web for the lyrics; the search would give me a title and artist names;
I then would try to check the sound on the tape against recordings
of the songs that I looked for in their
preview versions on e.g. iTunes or Amazon's.)
Nowadays I can do much, much better using online music recognition services like the Shazam application on my iPhone. (Still only in the case of pop(ular) music, though.)
For many years I had wished for such a powerful tool to help me identify audio fragments on the tapes I picked up. I wanted an audio search engine, something like a GoogleSound, which would allow one to upload parts of a sound file, upon which the engine then would return title, artist and maybe even a preview as results. I honestly thought that gentle giant Google would attempt to create a service like this. For a while I even toyed with the idea of applying for a job at Google's (that was the time Google was hiring at a mega-scale), thinking specifically of - research / datamining - work somehow related to audio file search and indexing.
A service like the one these days provided by e.g. Shazam is precisely the thing that I was hoping for, but which I thought still far beyond our algorithmic and computational reach.
 Until the day I first saw
the app perform its 'magic'.
Until the day I first saw
the app perform its 'magic'.
...
For those who do not know Shazam, here is how the app works: you are somewhere
hearing some (recorded) music playing and say to yourself: "Stop, hey,
what's that sound?" ( * ) ... You then pick up
your iPhone, launch Shazam, click its tag button, and point your
mobile's microphone towards the source of the music. The app 'listens' for
about 15 seconds. During that time it records a sound clip which then is
sent to the Shazam server. Shazam runs its pattern recognition algorithm,
that looks for a recording in the database with an audio
fingerprint (contructed from a series of intensity peak frequencies,
as derived
from the audio file's spectrogram) which matches that of the sample.
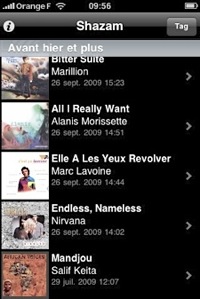
If close enough, the closest match will be the result that appears on your
phone's screen within seconds. The screen shot shows you some of the 'found
music' that the app recently recognized for me.
The algorithm developed by Avery Li-Chun Wang and others at Shazam is remarkably powerful. Pretty much all of the popular music I searched for was recognized; even if its origin was slightly less western, as for example in the case of turkish popular music. It is not infallible, though, and while testing the app I did come across curious and obviously incorrect results every now and then; so if the answer is of some importance, one should always verify, and not take Shazam's word for it. But the algorithm proves itself an amazingly reliable guesser; though it will, obviously, only identify recordings that have been fingerprinted and added to the Shazam database. That base currently contains about 8 million recordings. Which is impressive enough, though surely it is but a tiny part of all the recordings in the world. Very true: "Most sounds you will never hear, " once said Penelope, with a sigh accompanied by the strangest of little smiles. It left me wondering what she meant precisely, or that maybe she was merely being ironic.
Shazam is a commercial enterprise, that - at least publicly - is concentrating all of its efforts on recordings of popular music. As far as I understood it, the method will work equally well for recordings of other types of music. And what about 'sound recordings' in general? Field recordings? Interesting questions, trying to find the limits of the method. Are there classes of sounds that not let themselves be 'summarized', and 'recognized' via a 'fingerprint'? Would I be able to compose a sound y in a such way that it would fool Shazam into identifying it as recording x? And if so, what would a y sound like? Would y be unique, or are there many different y's? ... Wouldn't it be great to be able to experiment with this? It should be not so difficult for Shazam to create an interface allowing users to fingerprint private recordings and play around with this, but I guess this will be somewhat beyond their current business plan.
A comparable (and equally commercial) service, that I only recently found
out about and tested, is called Midomi,
by a company called Melodis
Corporation. Unlike Shazam, which is free, Midomi is a relatively pricy
iPhone app (€ 3.99). The algorithmic approach to audio file recognition used by Midomi is
also based
upon 'fingerprinting', but I do not know
how their Sound2Sound™ method
relates to that used by Shazam ( * ). Newcomer
Midomi compares well to Shazam:
it apparently makes use of a larger database; and
it will also try and identify a song that you
just sing or hum into the microphone.
Now you probably will be quick to believe
that my singing is no longer what it used to be in younger days. Nonetheless Midomi
did quite correctly identified my renderings of
(in that order) 'Vader Jakob', Amy Whinehouse's 'Rehab',
McCartney's 'Yesterday' and Ray Davies' 'Waterloo Sunset'.
Also, and contrary to Shazam, Midomi did recognize my Alban Berg
Quartet recording of Beethoven's Große Fuge. Only at second try
though, for at first it gave me
a Mozart Trio as result ...:-)
[ Added february 13th, 2010: Midomi meanwhile changed the name of its
music identification application to Sound
Hound. Overall, I actually find that Shazam is more straightforward its use and more reliable for my purposes. ]
Midomi btw is able to perform its 'singing trick' because it encourages users to record their singing online. As a registered user (and aspiring singer), you are invited to record your a cappella interpretation of whatever song or piece of music. Your efforts are added to the Midomi database. Fellow singers may listen to your singing, and can comment upon and rate your recordings. That is the carrot meant to get you to sing in the first place. All of the data thus collected are then used in the attempts to identify the clip sung or hummed by someone in search of a title's song... ("What's that sound?") That's a pretty smart and devious trick to compile and fill up an audio database.
All of this makes me wonder what lies ahead... I for one would like to have a local version of such an audio search application. Or an online interface that would allow me to fingerprint the files that make up my personal archive of audio recordings. I can think of an awful lot of fascinating ways in which these data then could be used and put to work. Finally, we might imagine the creation and use of a collaborative, universal database, to assemble fingerprints and data of 'all the recordings in the world' ... Or will the commercial interests of the owners of the principles of the audio search technology as above prohibit the development of non-commercial, 'open source', versions? Is there currently any substantial open-source work going on in this direction?
...
More on audio search later.
First let me finish writing "Alle Geluid van de Wereld".
...
It will be like a found tapes meta map.
[ previous Leipzig entry : Penelope Audela: das leipziger kleine ]
notes __ ::
(*) Chorus line from the Buffalo Springfield song
For
What's It Worth [ ^ ]
(**) The "Robust
and invariant audio pattern matching" used by Shazam, is the subject of a patent assigned in june 2003 to
Shazam Entertainment Ltd., with Avery Li-Chun Wang and Daniel Culbert as its inventors. [ ^ ]
Read all about Found Tapes, Foundtaping and Audio Cassettes (K7s) on the SoundBlog:
(2023, september 21) - Holland[s] Spoor
(2022, january 11) - 'The Art of K7', vol. 1
(2021, september 11) - The Art of K7 :: Sudokaising [ii] Time Folds
(2020, march 21) - The Art of K7 :: Sudokaising [i]
(2019, november 17) - Foundtapers & Foundtaping in Porto
(2019, februay 08) - CCNL :: Cassette Culture in Linz, Austria
[ii] The aesthetics of erasure
(2019, januay 18) - CCNL :: Cassette Culture in Linz, Austria
[i] Oral history
(2015, november 22) - Situasonnisme: the City Sonic Festival
(2014, june 19) - Lecture de Cassette
(2013, october 25) - The Art of K7 (prelude) [sketch/book, 1]
(2013, march 23) - "Ma première cassette était vierge..." Mourning & celebrating 50 years of compact cassette
(2012, july 26) - UnOfficial Release
(2010, november 28) - Foundtaping, Maps & Shadows
at the Basel Shift Festival (i.)
(2009, november 15) - prof. dr. Cassette
(2009, november 08) - A found tapes meta-map
(2009, october 22) - Founded Tapapes
(2009, september 20) - Found Lost Sound
(2009, july 26) - "You, a bed, the sea ..." [ 1. Athens, sept. 28th 1994 ]
(2009, may 23) - It feels like summer in the city [KT2009, i]
(2009, february 19) - Time and the weather - "? Footage or Fetish" @ Käämer 12, Brussels (ii)
(2009, january 30) - A Tingel Tangle Tape Machine - "? Footage or Fetish" @ Käämer 12, Brussels (i)
(2009, january 15) - Kassettenkopf
(2008, december 08) - un-Tuned City (foundtaping in Neukölln)
(2008, september 14) - Psycho/Geo/Conflux in Brooklyn, NY __i.
(2008, august 31) - " Le chasseur " (foundtaping in brussels_ii)
(2008, june 18) - "Sing Laping, Sing !" (foundtaping in brussels_ i)
(2008, january 06) - Mo' Better Mo-Tapemosphere, 2. Restmuell
(2007, june 16) - Mo' Better Mo-Tapemosphere, 1. "chase away all my fear"
(2007, march 07) - Back to Berlin 2. Found Tapes
(2006, september 28) - jenny likes poets
(2006, september 06) - the sound of almost-no-more words
(2006, june 13) - fotex #49-51
(2006, june 04) - Sonofakunsttoer
(2006, april 17-25) - 'sudoku-solution' in 'de nor'
(2006, january 19) - ride, buggy, ride ... !
(2006, january 13) - axiologie for dummies
(2005, november 06) - found in maastricht
(2005, august 28) - tête-de-tettine / tête-de-cassette
(2005, august 23) - tape busters and coordinates
(2005, july 02) - Conquering America ...
(2005, june 03) - stationed soother
(2005, april 21) - Low-fi : the new Readymades
(2005, march 24) - d_Revolution #1 ...
(2005, february 07) - found tapes for spies
(2005, january 28) - "parfois l'amour tourne à l'obsession ..."
(2004, november 06) - à la tranquilité
(2004, july 20) - instructions in arabic
(2004, may 08) - phound stufphs
(2003, august 04) - new acquisitions #7, #8
(2003, may 04) - r2r
(2003, april 24) - splice and tape
(2003, april 15) - new acquisitions #5,#6
(2003, january 09) - finders keepers
(2002, november 24) - exhibit #4
(2002, november 08) - what fascinates me
(2002, november 07) - more on found tape montage
(2002, september 14) - detour
(2002, september 09) - 2 down, 3 to go
(2002, september 06) - magnetic migration
Read about Found Tapes in Gonzo (Circus) [Dutch]:
Gonzo #163, mei/juni 2021 - Lang Leve Lou Ottens
Gonzo #137, januari/februari 2017 - Het Kaf en het Koren
tags: acoustic fingerprint, found tapes, maps, soundmap, iPhone, Penelope Audela
# .335.
smub.it | del.icio.us | Digg it! | reddit | StumbleUpon
comments for A found tapes meta-map ::
|
Comments are disabled |