11 min read 🤓
Culturomics, n-grams & sound artists
february 14, 2013.
He is intelligent, he is thoughtful,
he is a sound artist ( * )
Data, Babe, Babel, Car and Can
All things thinkable have been or soon will be digitized. After which it will be the turn of much that until not so very long ago was unthinkable - digitized. Data is the 21st century gold that many are chasing - feverishly. As suggested by the frequency of the use of the words 'data' and 'gold' in Google's digitization of about 6% of all the books that have ever been published [the English part of this corpus alone comprises about half a trillion of words - that is 5 x 1011 = 500.000.000.000 ( ** )], it was as of the end of World War II that our interest in Data started to get bigger than our interest in Gold...
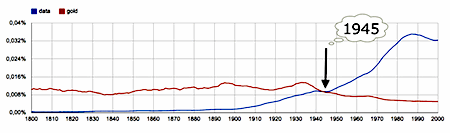 |
data, gold - unigrams, English 1800-2000 |
Everything can become data. Data are everywhere. In and by itself that's nothing new. What is new is our ability to collect and store them in sheer cosmic quantities, and to subsequently have machines assist us in using and perusing all of them, at but little under the speed of light.
All of the world's libraries, collections and archives, wherever and whatever they are, be it official (institutional) or unofficial (personal), contingent or intentional, are among the 21st century's data/goldmines. Near to all of the world's recorded sounds and music, every movie that has ever been made and all of our photographs are examples that already feel blatantly obvious... A little less trivial (but not a lot) are all of the events and all of the givens of all of our lives; and whatever there is that can be retraced and recovered related to that of our ancestors. (Most of it will be true [verifiable facts], though a not negligible and increasing part of it will be false [the fictions].) The idea that we indeed are well on our way compiling something closely resembling a Library of Babel is getting less farfetched by the hour. ( *** )
___⟥⫷⟕⟖⫸⟤___
[ A little while ago I read an e-book version of Philip K. Dick's Confessions of a Crap Artist. I was kind of amused by how Dick regularly (but not always) used the word can for car, like in the following fragment (a screenshot from my iPad's iBooks):

Given the stuff that most cars are made of, naming a car a 'can' seemed an interesting choice, and actually not that strange. It matched the originality that I had come to expect of an author like Dick. It therefore took quite a while before I realized that the use of 'can' for 'car' in the novel was not innovative language, but a digitization (OCR) error. Which I was able to confirm via a scanned version of an edition of the book available at Google books:

But is it not likely that in the long run and in many cases it will become impossible to discriminate between different versions of digitized 'things'? ]
___⟥⫷⟕⟖⫸⟤___
Digitization of all of our (documented) history and of all of our (documented) culture is part of the very intentional efforts of Big Time Data Chasers, like a Google or a Facebook. Their corporate hearts pump data like blood. Data is their capital. It's their raison d'être. But not less important are the largely uncoordinated and unintentional - but nevertheless joint acts - of millions of women, men and machines; the you's and me, the everyone's, sharing digitized texts and media, communicating with family, friends, acquaintances and the occasional stranger, via laptops, tablets, smartphones et cetera. Along with the streams of text, images and sounds that we are pumping out, pumping in, day after day after day, we ourselves are the data, washing up somewhere, becoming a part of... well, yes, of a what indeed? A Data Pie?
The utopian, idealistic slogans about data and information wanting and needing to be free notwithstanding, most Data are not (free), and, unless one day soon we manage to re-boot this world in some other than a (version of a) capitalist system's mode, it is highly unlikely that they ever will be (free): the world is sharing its data the way it has been sharing its gold; they way it is sharing its oil, and they way it is sharing whatever other of its resources. This then, of course, explains the data rush and fever, which has armies of diggers battling for control, over some part, any part, of the Data Pie.
___⟥⫷⟕⟖⫸⟤___
"Wollt ihr die totale Digitalisierung?" - Google Books' Ngram Corpus
The Google Books project's ultimate goal is the complete and unabridged digitization of all the (different) books, magazine, papers, of all the printed stuff that currently is physically present in our world. According to Google's own estimation, as far as books are concerned: there should be about 126 million of them. Of these 126 million, Google digitized the quite decent number of some 15 million (though the New York Times estimated that volume to be at least 25 million), resulting in a corpus of digital text that corresponds to, roughly, something between 12% and 20% of all of the text that has ever been published in book form. It is a matter of (author's, publisher's and other) rights that only a small part of these millions of books can be read at Google's. But it is possible to search the full text of all of the books. This is what enabled me to verify that indeed Philip K. Dick did not use the word 'can' as a synonym for 'car'.
The gigantic quantity of digitized printed text at Google's was grist to the mill of linguists and social scientists working in the currently quite fashionable field of digital humanities. Their idea was to use these data to try identify and analyze linguistic and cultural trends that surely must be reflected in millions of books written over the past five centuries. They came up with the neologism culturomics (cf. genomics) as a name for the study of human behavior and cultural trends via the quantitative analysis of digitized texts ( ** ).
I was reminded of all of this while reading Eduardo Navas's Remix Theory: The Aesthetics of Sampling. A disappointing work on an important and fascinating subject, but what matters here is that in his book Eduardo reproduced a whole series of graphs showing the popularity-in-print between 1800 and 2008 of some of the terms relevant to his research: like 'recording', 'sampling', 'remix', 'remix culture', and others. These graphs are based upon an n-gram corpus (for n = 1 up to n = 5) derived from Google's digitized Books collection.
The great thing about this particular set of data: it is available as a (huge) free download for whoever wants and try to use it. Even better: Google Books enabled an online Ngram viewer, which gives anyone with an internet connection and a web browser the means to try his/her hand at culturomic research.
So, please allow me to entertain you with some facts derived from the Google Books Ngram Corpus. All of them dug up for the fun of it. You are allowed a smile. But note that it has not been my intention to downplay a great tool that has evident potential. One may only wish that ever more data collections and data analysis tools will be made public in similar ways... A task, indeed, for any Ministry of Data, worthy of that name ...
___⟥⫷⟕⟖⫸⟤___
[ In view of last century's sexual revolution it will not come as a big surprise that the number of occurrences in print of the unigram fuck, being negligible earlier on in the 20th century, has been steadily increasing ever since the 1960's.
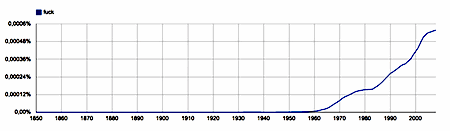 |
fuck - unigram, English 1850-2008 |
Curiously, though, going back in time as far as the 16th century, there seems to be a great deal of 'fuck' in print also from the early 17th until the early 19th, a period of almost two centuries.
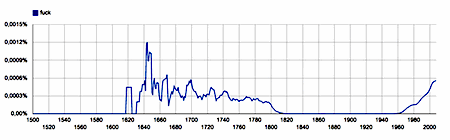 |
fuck - unigram, English 1500-2008 |
This, however, is not an indication of a sexual morality that back then was far freer than in the 19th and first half of our 20th century. It actually is due to a 'digitization glitch'. Google Books allows us to check (some of) the occurrences of the n-grams showing up in the graph, which in this particular case quickly revealed that it is 17th century print occurrences of 'such' or 'suck' that are read by the OCR as a 21st century 'fuck', as in the following example, from Edmund Southerne's Treatise concerning the right use and ordering of bees, from 1593.
 |
... ]
___⟥⫷⟕⟖⫸⟤___
On the frequency of occurrences and the semantics of sound art & related terms in the 2012 Google Books Ngram Corpus
The graphs in Eduardo Navas's book had me wonder whether the Google Books Ngram Corpus would corroborate the generally held view that the term (bigram) sound art as a designation for a diverse group of art practices that considers wide notions of sound, listening and hearing as its predominant focus (Wikipedia, February 14th 2013) indeed came into common use only as of the late 20th century. The earliest documented use is held to be (the catalogue for) a show called Sound/Art, at The Sculpture Center in New York in 1983. It therefore seemed a reasonable hypothesis that the Google Ngram Corpus would show up little or no occurrences of the bigram 'sound art', until the early 1980's. After that year we'd imagine the number of its occurrences in print to steadily increase. The graph indeed shows the expected increase after 1980. Surprisingly however, it also shows that the bigram 'sound art' is found abundantly in print publications that appeared long before the 1980's: 'sound art' seemed to be especially 'in vogue' between 1890 and 1940.
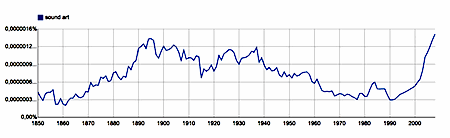 |
sound art - bigram, English 1850-2008 |

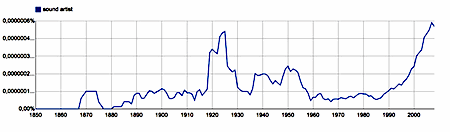 |
sound artist - bigram, English 1850-2008 |
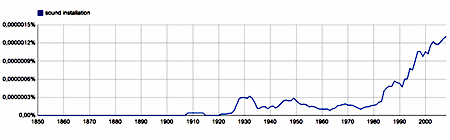 |
sound installation - bigram, English 1850-2008 |
A similar phenomenon is at work in the graph of the print frequency of the bigram 'sound artist'. The graph for the bigram 'sound installation', on the other hand, corresponds more or less to what one would expect for the naming of a certain category of works of art, that only became relatively common towards the end of the 20th century. Note however that 'sound installation' is not only used as a name for sonic art works. It is (or was) also quite commonly used to talk about sound amplification systems. For a similar reason of semantic ambiguity, the frequent use of 'sound art' and 'sound artist' in the first half of the 20th century does not hint at a forgotten period in the history of music or the use of sound within the arts. What it does suggest, though, is a shift in the semantics of these bigrams. Apart from the fact that in a (small) number of cases before as well as after the 1980's, sound art is used as a synonym for music, before the 1980's - and especially in between 1890 and 1940 - the bigram 'sound art' is mainly used in the sense of a 'healthy art'. Similarly, critics in the first half of the 20th century would call an artist a 'sound artist', if they considered him/her to be a good artist, a competent one. (See the graph for the bigram 'sound artist' and the motto of this article.) But towards the end of the 20th century the semantics of the bigram 'sound art' changes. Nowadays hardly anyone will qualify an artist as competent by applying the adjective 'sound'. Indeed, 'sound artist' has come to mean: an artist, in general other than a musician, who is working with sound as (part of) his or her material.
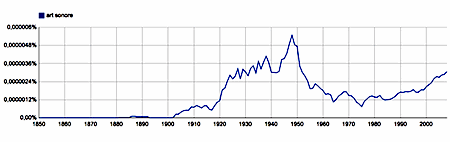
Similar semantic shifts must be at work in the usage of the French and Spanish translations of sound art: art sonore and arte sonoro.
 |
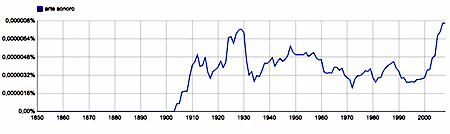 |
art sonore, arte sonoro - bigrams, French/Spanish 1850-2008 |
Being a unigram, the German term for 'sound art, 'Klangkunst', is pretty much unequivocal. The graph shows how in German books Klangkunst booms as of the early 1990's.
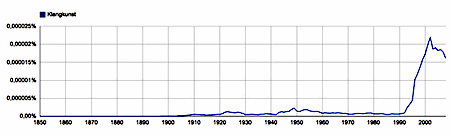 |
Klangkunst - unigram, German 1850-2008 |
(Instead of 'sound art', sometimes the bigrams 'sonic art' or 'audio art' are used. These are far less frequent, but also semantically far less ambiguous.)
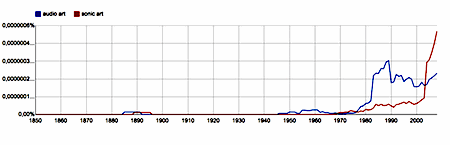 |
audio art, sonic art - digrams, English 1850-2008 |
[ Copycatting Google Books (this is not a criticism), Vladimir Viro has developed an online n-gram viewer for music, which displays graphs that show you how over the years e.g. a certain melody (a sequence of notes) occurred in a corpus of musical scores. That's interesting, of course. But I did not yet grasp how (and whether) one could use these music n-grams in order to reveal 'trends in music' ... ]
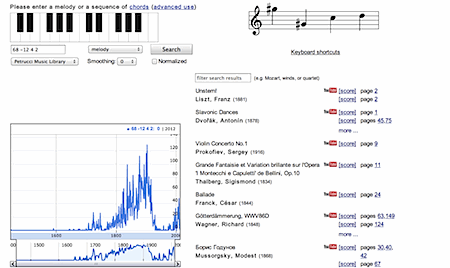 |
Added summer 2019
Dutch readers may find some more thoughts on the Google Books project and the politics of mass digitization in "Hoedje van, hoedje van" - Over papier, berekenen en betekenen, the sixth paper in my series of HoofdStuk essays ("Ieder HoofdStuk is een Head Shot") in the 150th print edition of the Dutch music and art magazine Gonzo (Circus), march/april 2019.

 |
 |
 |
 |
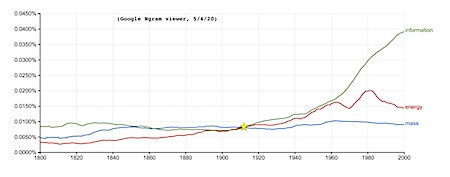
[ added Sunday April 5th 2020 : I recently had the Ngram viewer draw its lines for energy, mass and information; there is something eery about seeing that mass and energy got equal in the very days that Albert Einstein developed his stunningly deep thoughts on these matters; with information then in the final decades of the past century elegantly surpassing both...]
...
notes __ ::
(*) — but there come moments when a dead hand falls upon him, and he is once more [...] snuffing absurdly over imbecile sentimentalities, giving a grave ear to quackeries, snorting and eye-rolling with the best of them. In: H.L. Mencken - A Book of Prefaces (1917) [
^ ]
(**) Jean-Baptiste Michel et al. Quantitative Analysis of Culture Using Millions of Digitized Books. Science, January 2011: Vol. 331 no. 6014. (
Yuri Lin et al. Syntactic Annotations for the Google Books Ngram Corpus. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, 2012. (pdf) [
^ ]
(***) Added January 2019: I wrote —in Dutch— on Borges' library and Jonathan Basile's online algorithmic interpretation of it in issue 146 (juli/augustus 2018) of Gonzo (Circus) Magazine: Aan Tijd geen Gebrek [
^ ]
tags: culturomics, n-grams, sound art, syntax, semantics, language
# .433.
comments for Culturomics, n-grams & sound artists ::
|
Comments are disabled |